Written by Isabel del Castillo (COO) and Mario Alejandro Rueda (Junior C++ Developer)
1. What is lock-free programming?
Lock-free programming refers to a programming paradigm that aims to design concurrent algorithms and data structures that do not rely on locks or other blocking synchronization mechanisms.
In lock-free programming, multiple threads or processes can operate on shared data structures simultaneously without causing contention or requiring explicit locking mechanisms.The main objective of lock-free programming is to ensure progress in the face of concurrent execution. Traditional locking mechanisms, such as mutexes or semaphores, can introduce synchronization overhead and potential bottlenecks when multiple threads contend for access to shared resources. Lock-free programming aims to mitigate these issues by allowing concurrent access to data structures without blocking or waiting for locks.
Lock-free algorithms typically utilize low-level synchronization primitives, such as atomic operations and memory barriers, to ensure data consistency and integrity. These primitives provide atomicity guarantees, meaning that their execution appears instantaneous and cannot be interrupted midway by other threads.
By employing lock-free techniques, developers can design highly scalable and efficient concurrent systems. Lock-free programming is especially useful in scenarios where high performance, low latency, and fine-grained parallelism are critical, such as real-time systems, high-frequency trading, and concurrent data processing.
However, it’s important to note that lock-free programming is a complex and advanced topic. It requires a deep understanding of memory models, atomic operations, and concurrent algorithms. Additionally, designing and implementing correct lock-free algorithms can be challenging due to the potential for subtle race conditions and data inconsistencies. Therefore, careful consideration and rigorous testing are necessary when utilizing lock-free programming techniques.
2. What is a Map in object oriented programming?
In object-oriented programming (OOP), a Map is a data structure that stores key-value pairs for efficient lookup and retrieval based on keys. It provides a way to associate values with unique keys, allowing quick access to data using the key as an identifier. Maps are commonly used for organizing and accessing data based on specific attributes or identifiers.
2.1 Map Operations
Before exploring the benchmark results, let's outline the definitions of the measured methods. The "put" method refers to the insertion of an element into a collection, while "get" pertains to accessing an element within the collection. Finally, "erase" involves the removal of an element from the collection
- What are we benchmarking in this article?
In the realm of software development, efficient Maps play a crucial role in optimizing performance. When it comes to Maps, different implementations exhibit varying characteristics and behaviors. In this article, we delve into a comprehensive benchmark analysis that measures the CPU impact of three key methods - put, get, and erase - across three distinct target classes: std::map, std::unordered_map, and a custom implementation called lockfree_hash_table_templated
3.1 std::map
The std::map class employs a Red-Black tree as its underlying data structure. For this class, the "put" method corresponds to std::map::insert, which exhibits a complexity of O(log N) in the worst-case scenario, where N represents the size of the map. Similarly, the "get" method corresponds to std::map::[] and std::map::at, both with a complexity of O(log N) in the worst case. Lastly, the "erase" method corresponds to std::map::erase, which has an amortized complexity of O(1), ensuring efficient deletion operations.
3.2 std::unordered_map
In contrast to std::map, std::unordered_map utilizes an open key hashtable implementation. When analyzing the "put" method for this class (std::unordered_map::insert), we find a complexity of O(1). However, in scenarios with multiple key collisions, the worst-case complexity becomes O(N) linear. Similarly, the "get" and "erase" methods (std::unordered_map::[] and std::unordered_map::erase) have an average complexity of O(1), but their worst-case complexities reach O(N) linear when dealing with successive key collisions.
3.3 LockFreeHashMap
The LockFreeHashMap is a custom implementation inspired by std::unordered_map. It offers an important distinction by incorporating lock-free mechanisms to prevent threads from becoming blocked while accessing the hash table. This feature proves invaluable in multithreaded environments such as Klepsydra's core classes, including EventLoop. The implementation of LockFreeHashMap can be found in the modules folder of the project. The "put," "get," and "erase" methods for LockFreeHashMap share similar complexities to std::unordered_map, all achieving O(1) time complexity in the worst-case scenario.
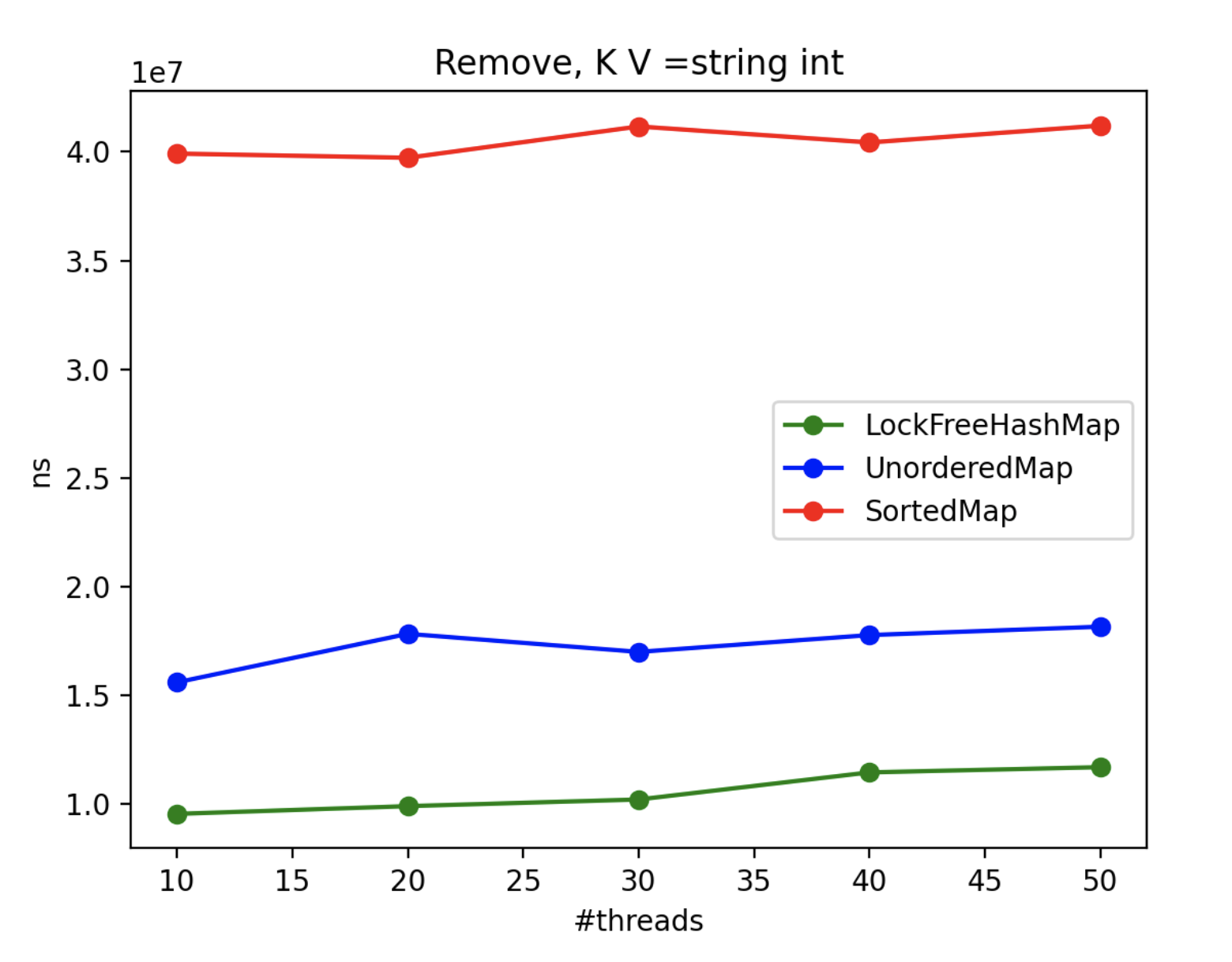
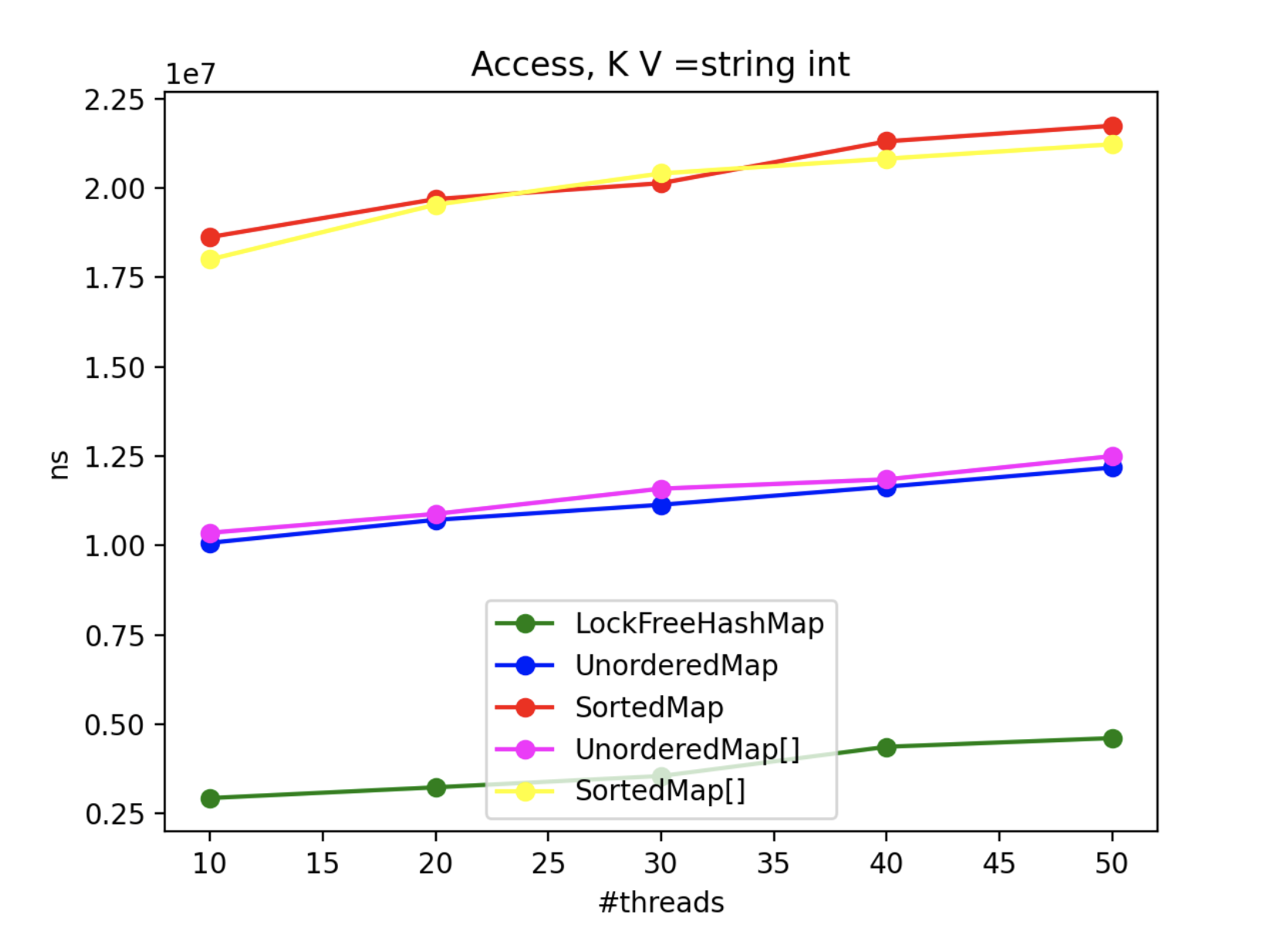
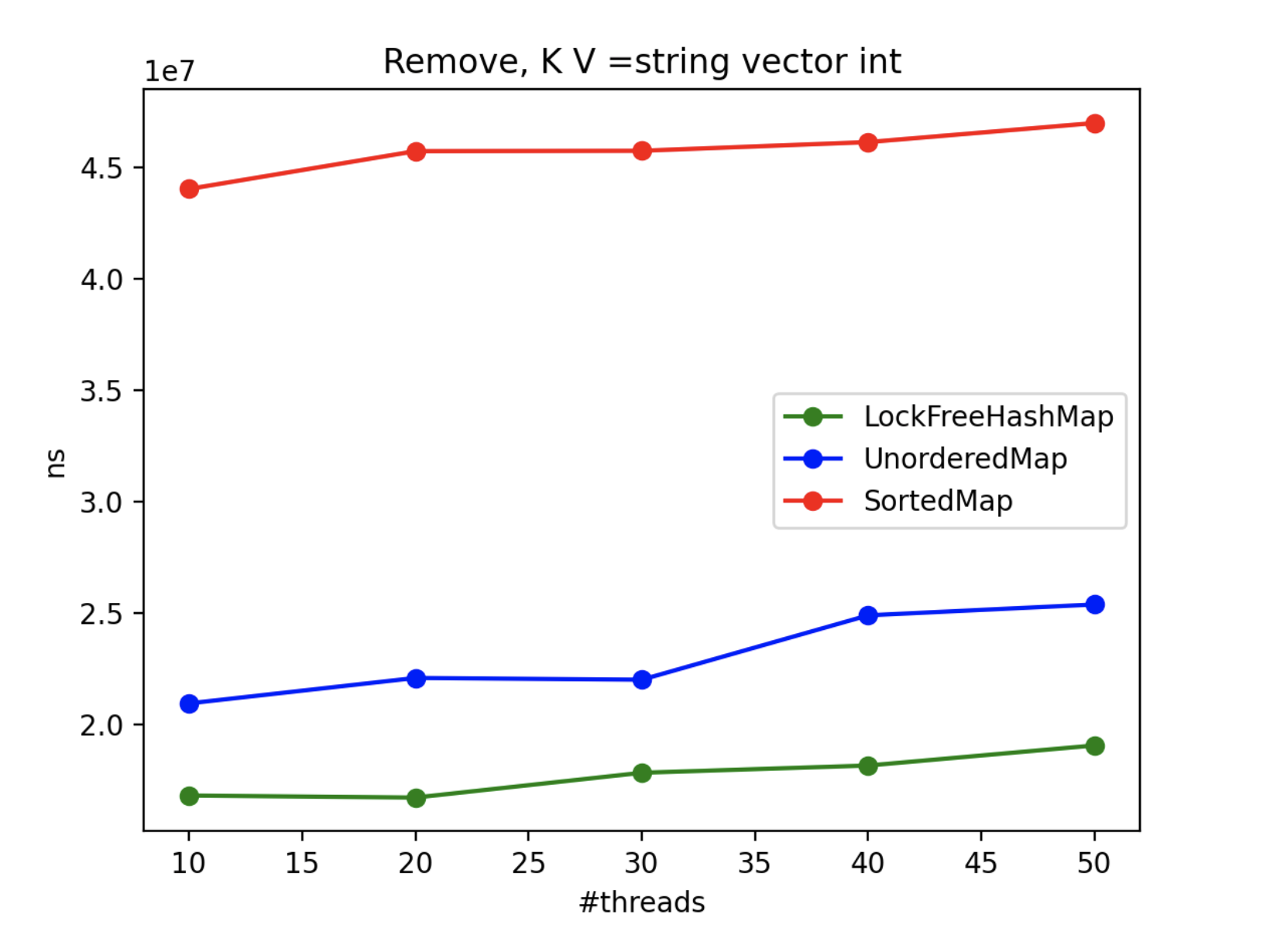
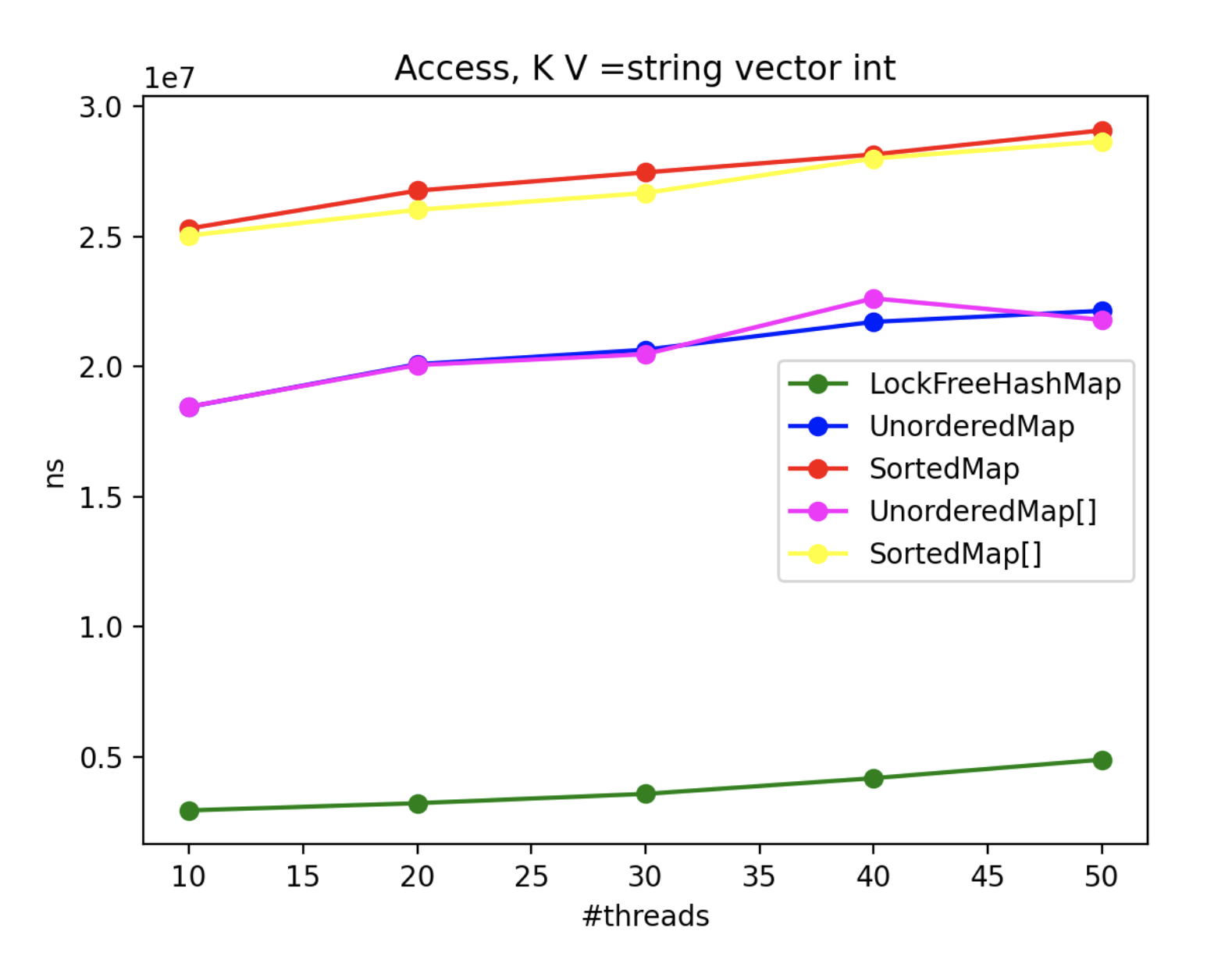
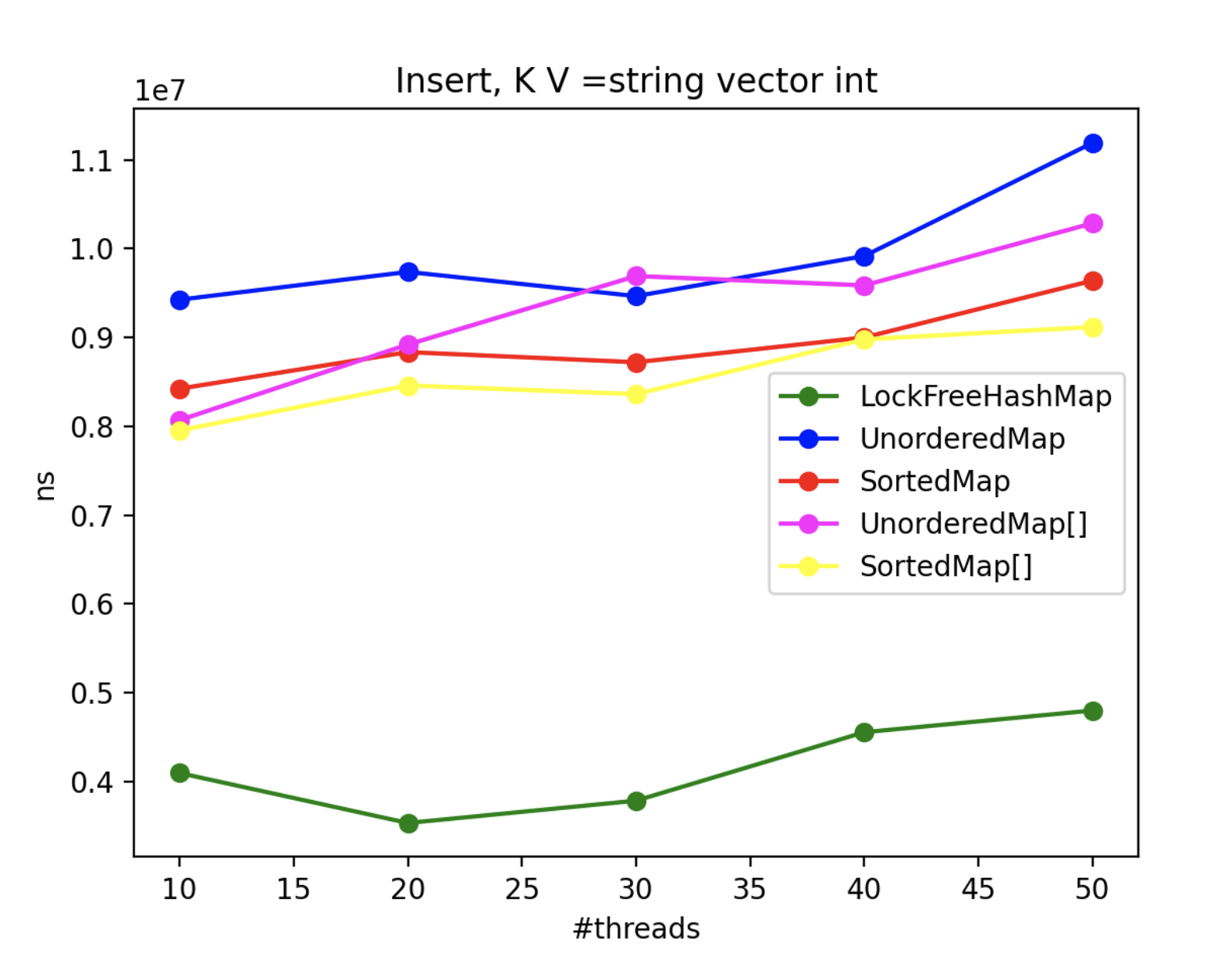
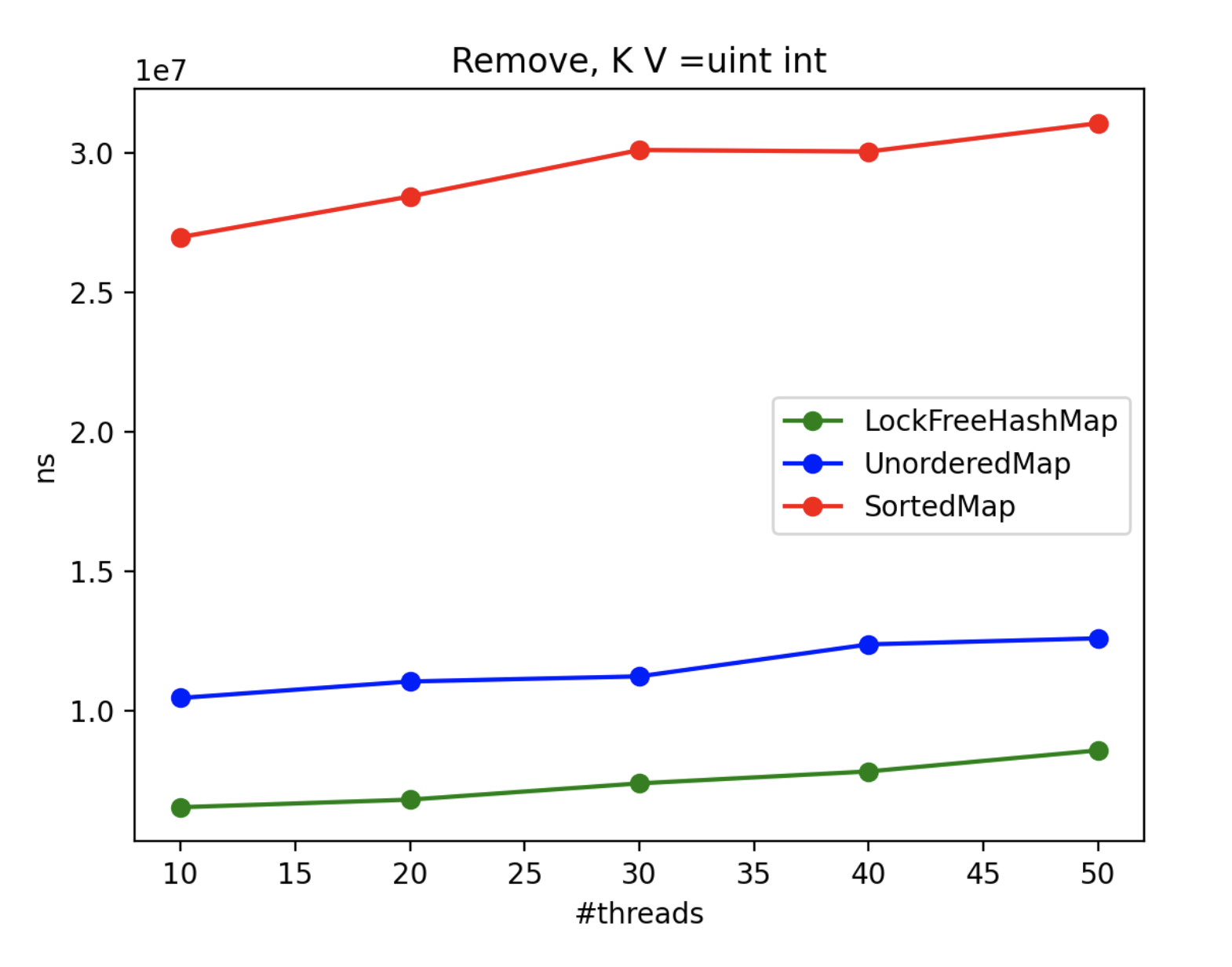
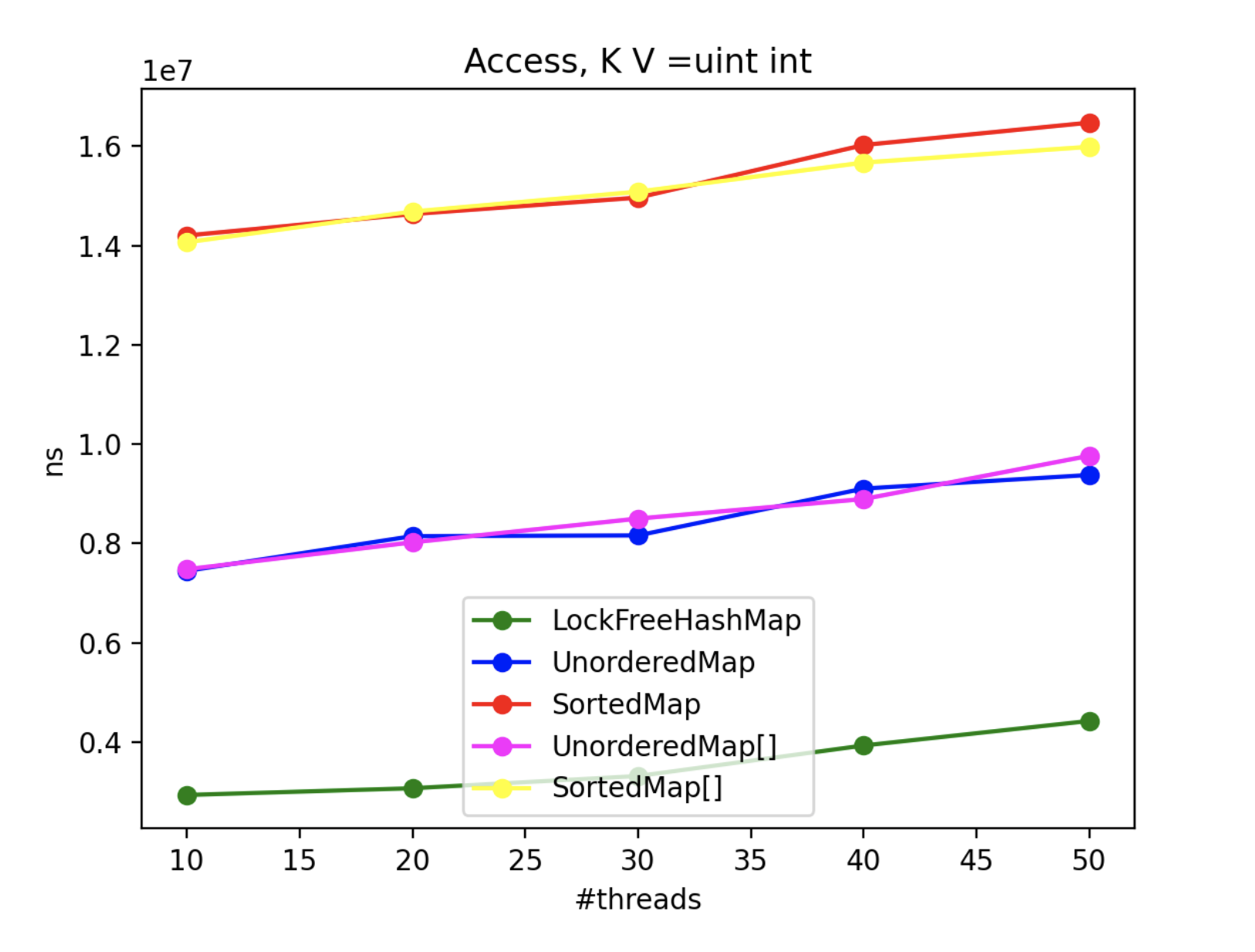
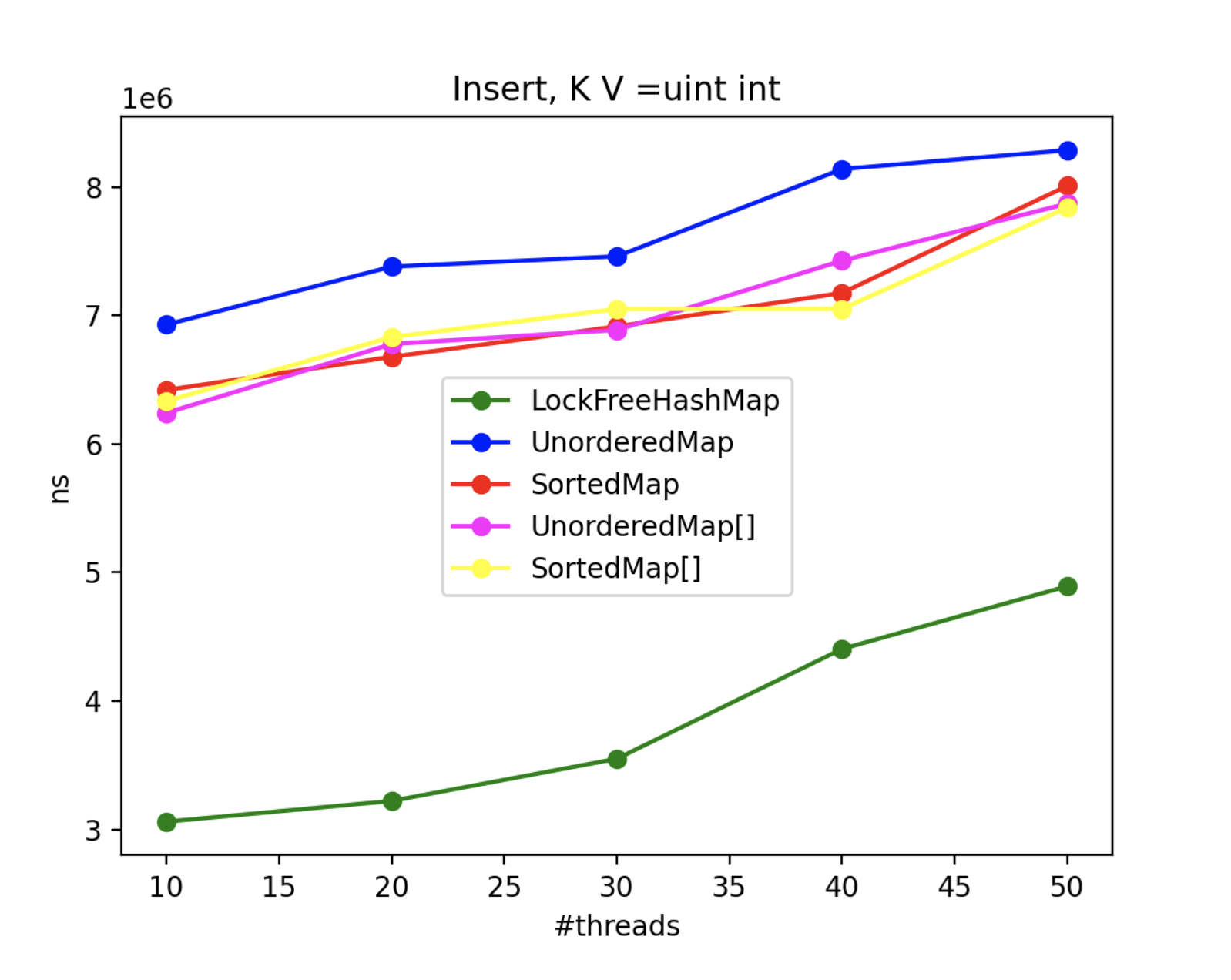
4. Multithread Results
To assess the advantages of using LockFreeHashMap in multi-threaded scenarios, we conducted an extensive benchmarking exercise. Since std::map and std::unordered_map lack inherent thread-safety, we encapsulated each operation within a locked block using a mutex. Throughout the benchmark, N threads concurrently performed the operations, with the exception of the “insert” operation, where one thread solely focused on inserting while N-1 threads attempted to access the collection. The real-time metric represents the maximum processing time (in nanoseconds) across all threads.
Graphics

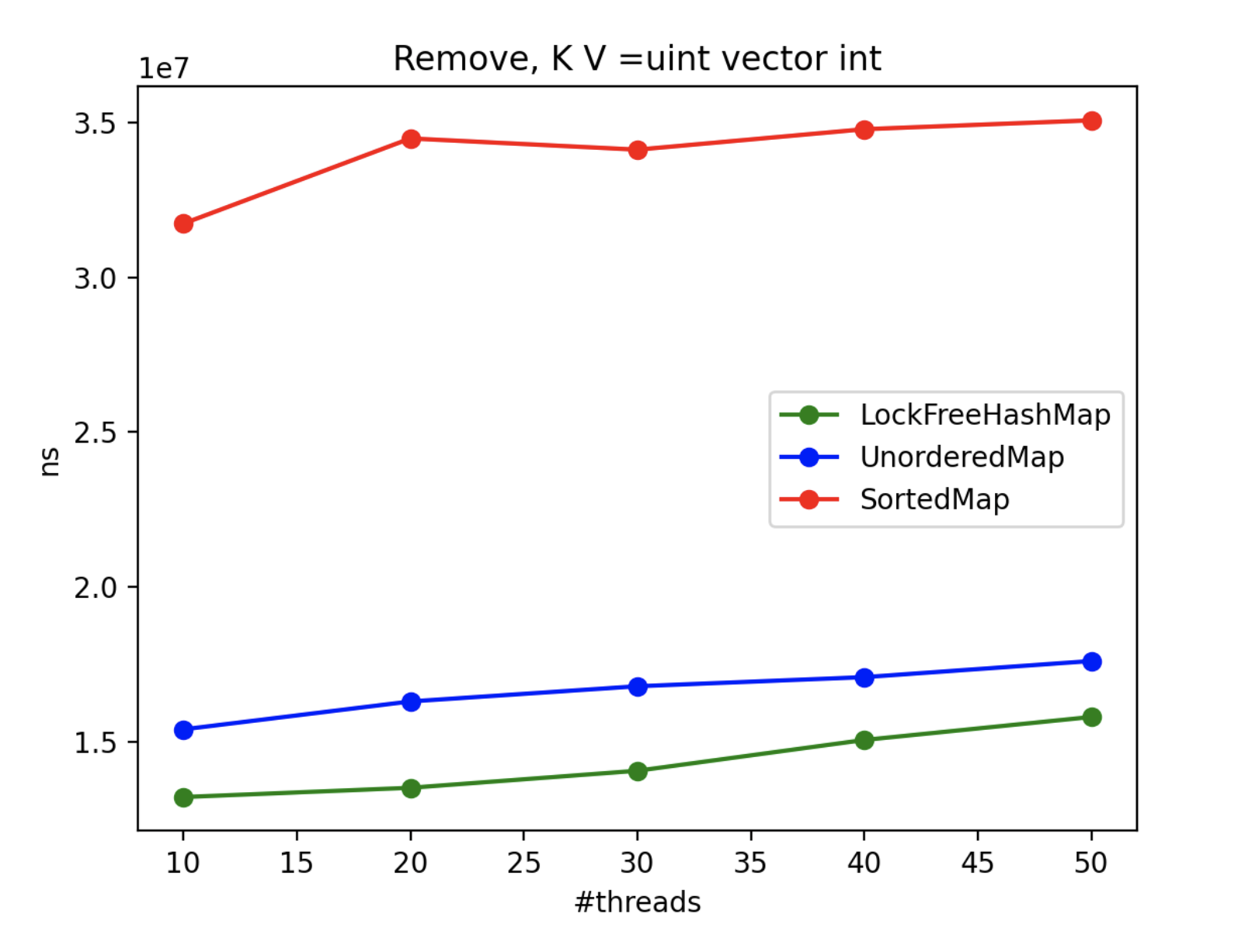
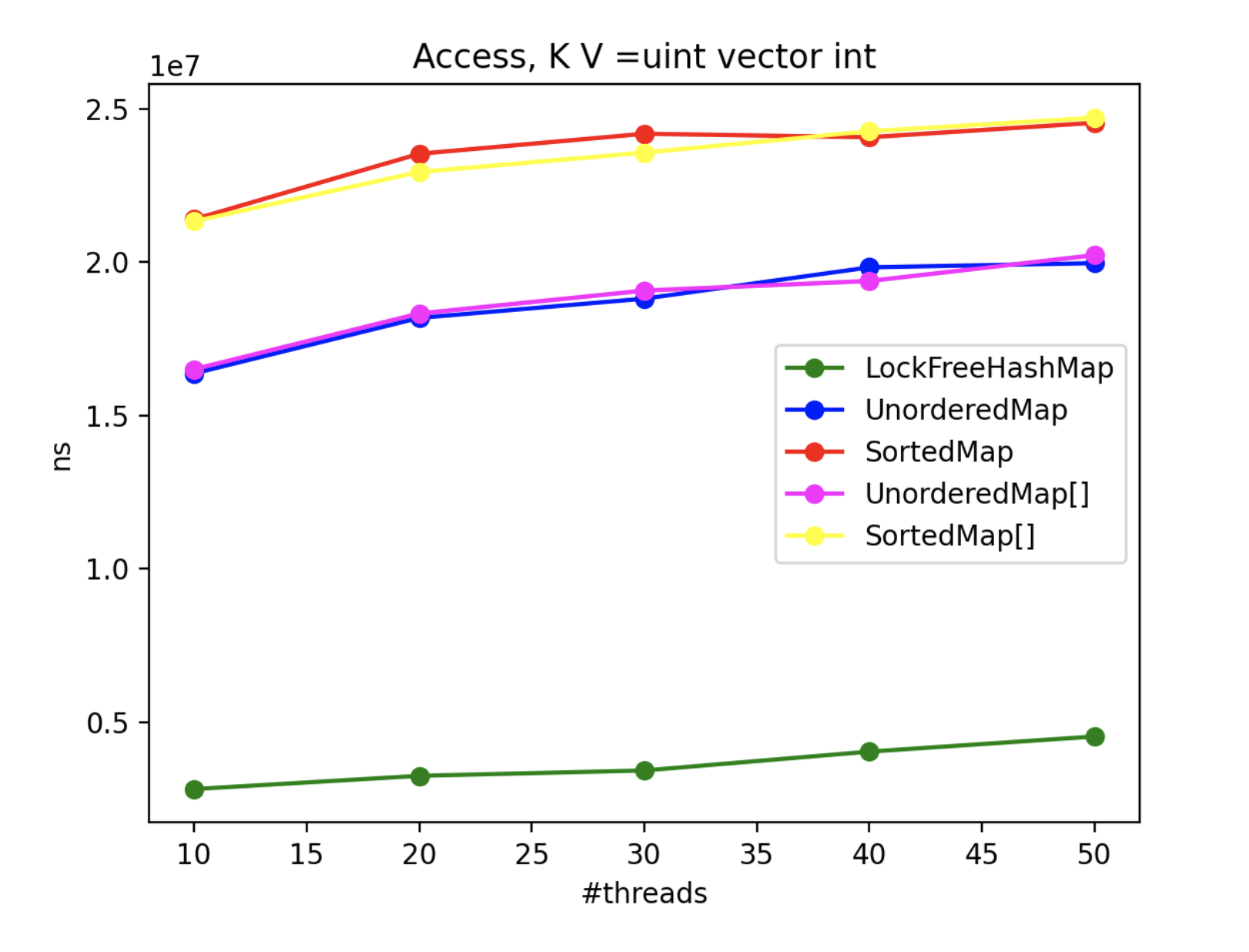
5. Conclusions
By scrutinizing the benchmark results, we gain valuable insights into the CPU impact of each method and class in multi-threaded contexts. These findings aid in making informed decisions when selecting the appropriate collection implementation based on performance requirements.
Klepsydra software leverages the power of lock-free maps and other advanced lock-free algorithms to deliver exceptional speed and minimize power consumption. These key features are fundamental to all our products, whether they are open-source or commercial. By utilizing lock-free data structures and algorithms, Klepsydra ensures optimal performance while prioritizing efficiency and power efficiency across its software offerings.